言葉の持つ情報や表す意味、感情等の適切な表現を模索
東京都市大学 情報工学部情報科学科 知識情報処理研究室 延澤 志保 講師
■キーワード
人工知能・知識情報処理・自然言語処理・語句認識・知識獲得・感情推定
■最近の研究テーマ
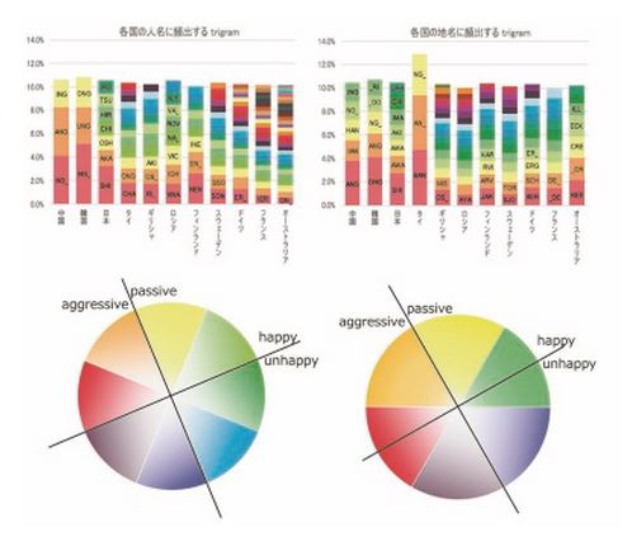
言葉やその構成要素である文字の持つ情報に着目し、若者言葉等や外国語表現、方言等、さまざまな語句や言い回しの自動認識で成果を挙げるとともに、固有名詞の自動言語推定等、これらの語句の属性や意味、原語句、印象の推定等を行うことで、話し言葉から専門文書まで幅広い文書の処理精度の向上を目指しています。また、文章理解や対話理解への応用を目標として、言葉に籠められた感情や印象、関連語句等の自動推定手法や、色情報等を活用して言葉の持つ情報を視覚化する手法の実現等に取り組んでいます。
■技術の特徴
人工知能技術を活用して文書中に現れるさまざまな情報を抽出し、その属性や意味、印象、感情等を自動的に推定することで、機械翻訳や対話処理等の精度向上はもとより、人間の感情に寄り添うことができるような温かく知的な技術の創出を目指します。
■技術の用途
機械翻訳や情報検索、自動要約、対話処理等、さまざまな言語処理で問題となる固有名詞や外国語句の埋め込み、新語等に起因する未知語問題の解決、また、評判分析等での、文脈を考慮した印象や感情の自動推定等が本技術の応用として挙げられます。
■企業等との連携可能テーマ
・文書群からの特有の知識情報の学習
・文書群からの語句認識、意図推定、印象推定、トピック推定等の情報抽出
・テキストマイニングおよび評判分析
■知的財産権・関連論文情報・著書
電子情報通信学会「知識の森」第6-3-3章「文字列探索」、2012年。
The Use of Domain-Specific Statistical Data for Japanese Morphological Analysis,Readings in Japanese Natural Language,CSLI,2016.
■研究内容と目指すもの
人口知能の一分野としての自然言語処理の立場から、文章中に現れるさまざまな情報を抽出し、その属性や意味を自動的に推定しています。言語は創造的かつ恣意的であり、固有名詞や若者言葉等の新しい言葉や言い回しの創造、外国語句の借用等が頻繁に起こるだけでなく、字面以上の意味や感情、印象を含むことも多々あります。未知の語句の自動認識、語句の属性や意味、印象情報や感情情報、周辺語句等の自動推定を実現することで、機械翻訳や情報検索、自動要約、対話処理等の自然言語処理の精度の向上を図るとともに、人間の感情に寄り添うことができるような温かく知的な技術の創出を目指します。
■お問い合わせ
東京都市大学
研究推進部 産学官連携センター
sangaku@tcu.ac.jp









